Symbolic Discovery of Optimization Algorithms
Chen, X.*, Liang, C.*, D. Huang, E. Real, K. Wang, Y. Liu, H. Pham, X. Dong, T. Luong, C. Hsieh, Y. Lu, Q. Le. *Equal contribution
NeurIPS, 2023
AutoML-Zero: Evolving Machine Learning Algorithms From Scratch
Real, E.*, Liang, C.*, So, D., and Le, Q. *Equal contribution
ICML, 2020
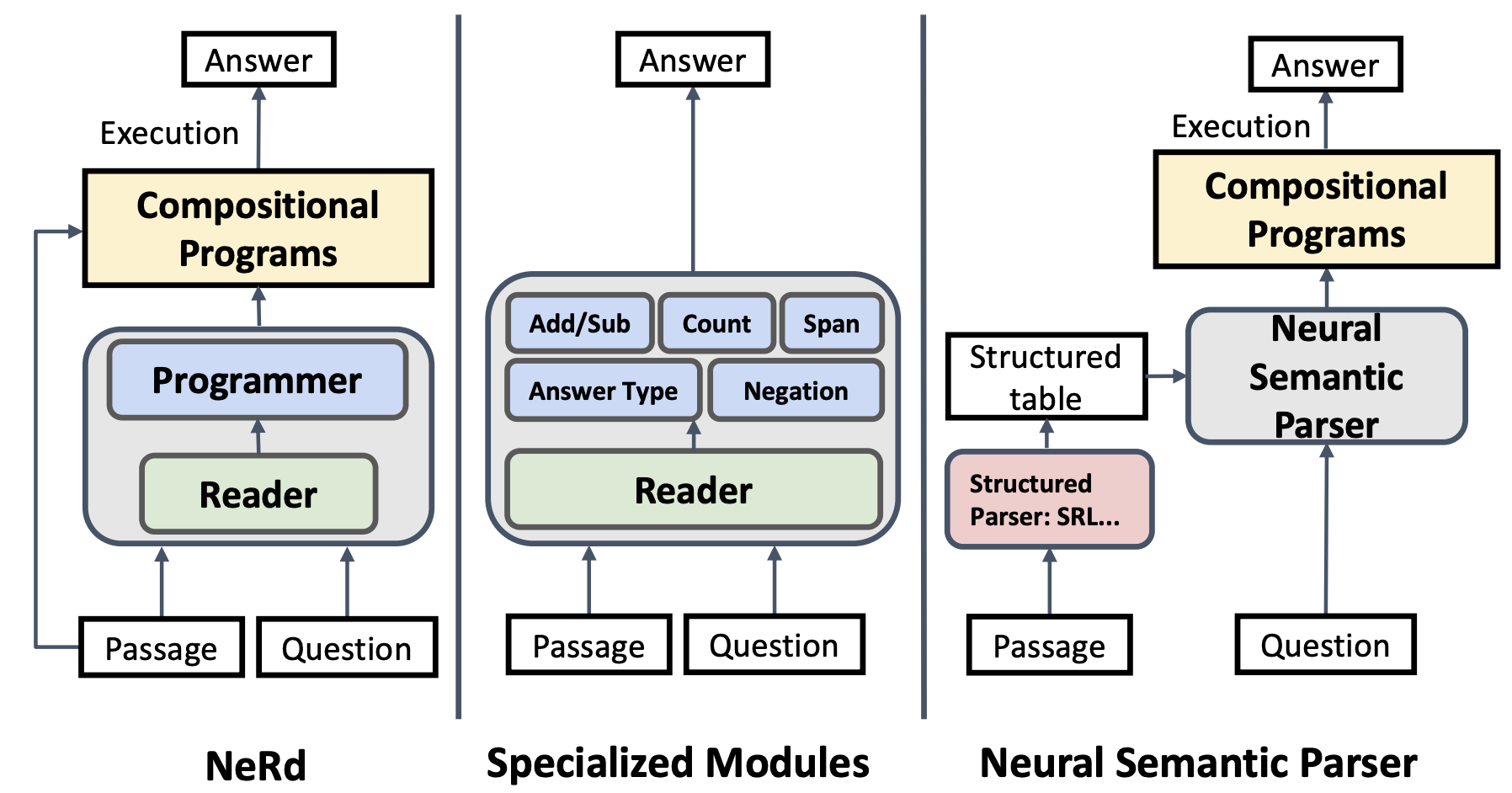
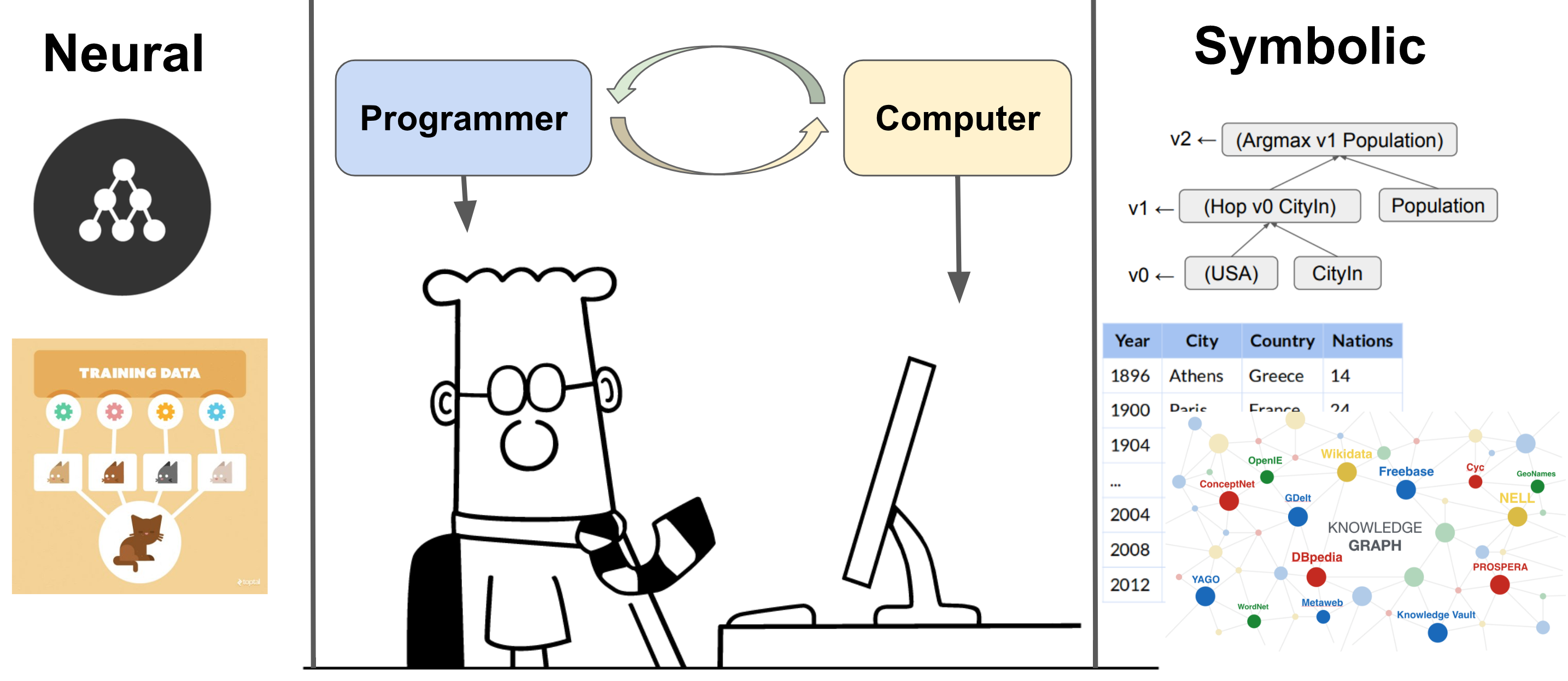
Neural Symbolic Reader: Scalable Integration of Distributed and Symbolic Representations for Reading Comprehension
Chen, X., Liang, C., Yu, A., Zhou, D., Song, D. and Le, Q.
Spotlight, ICLR 2019
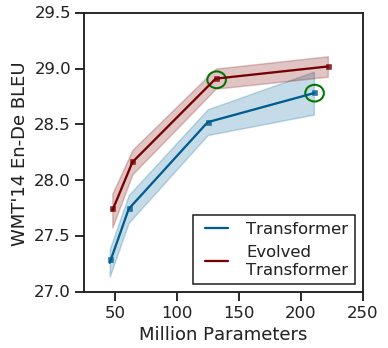
The Evolved Transformer
So, D., Liang, C., and Le, Q.
ICML 2019
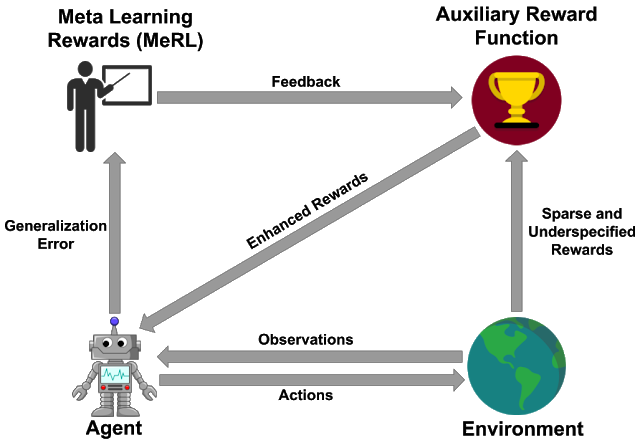
Learning to Generalize from Sparse and Underspecified Rewards
Agarwal, R., Liang, C., Schuurmans, D. and Norouzi, M.
ICML 2019
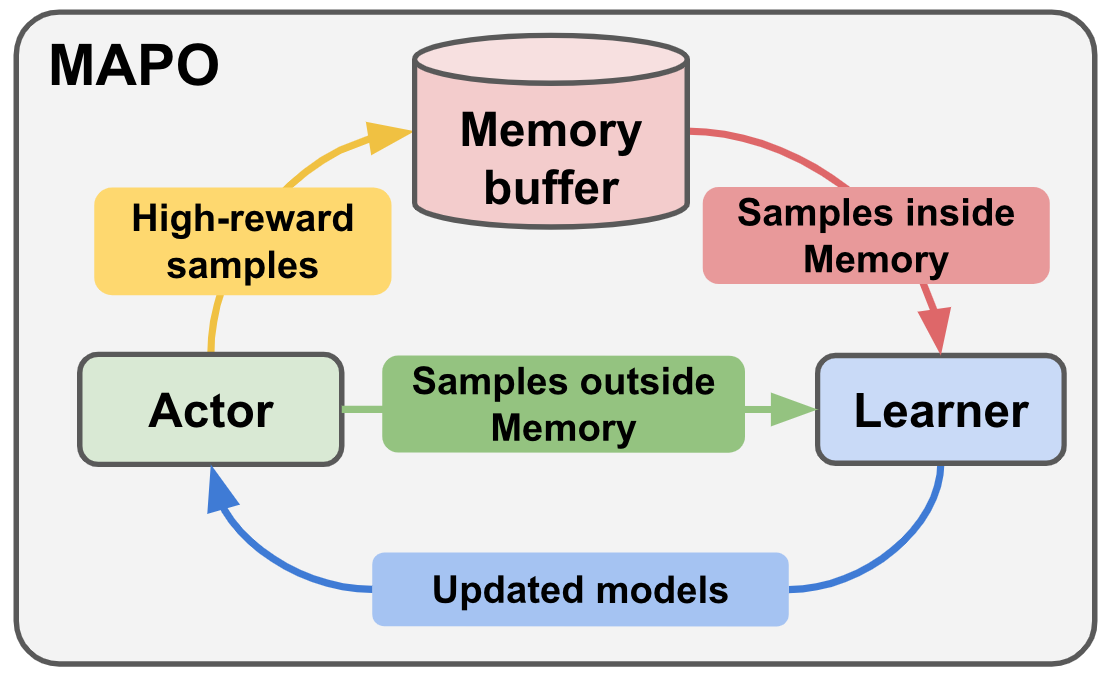
Memory Augmented Policy Optimization for Program Synthesis and Semantic Parsing
Liang, C., Norouzi, M., Berant, J., Le, Q., and Ni, L.
Spotlight paper (3.5% accept rate), NIPS 2018
Neural Symbolic Machines: Learning Semantic Parsers on Freebase with Weak Supervision
Liang, C., Berant, J., Le, Q., Forbus, K., and Ni, L.
Oral Presentation, ACL 2017
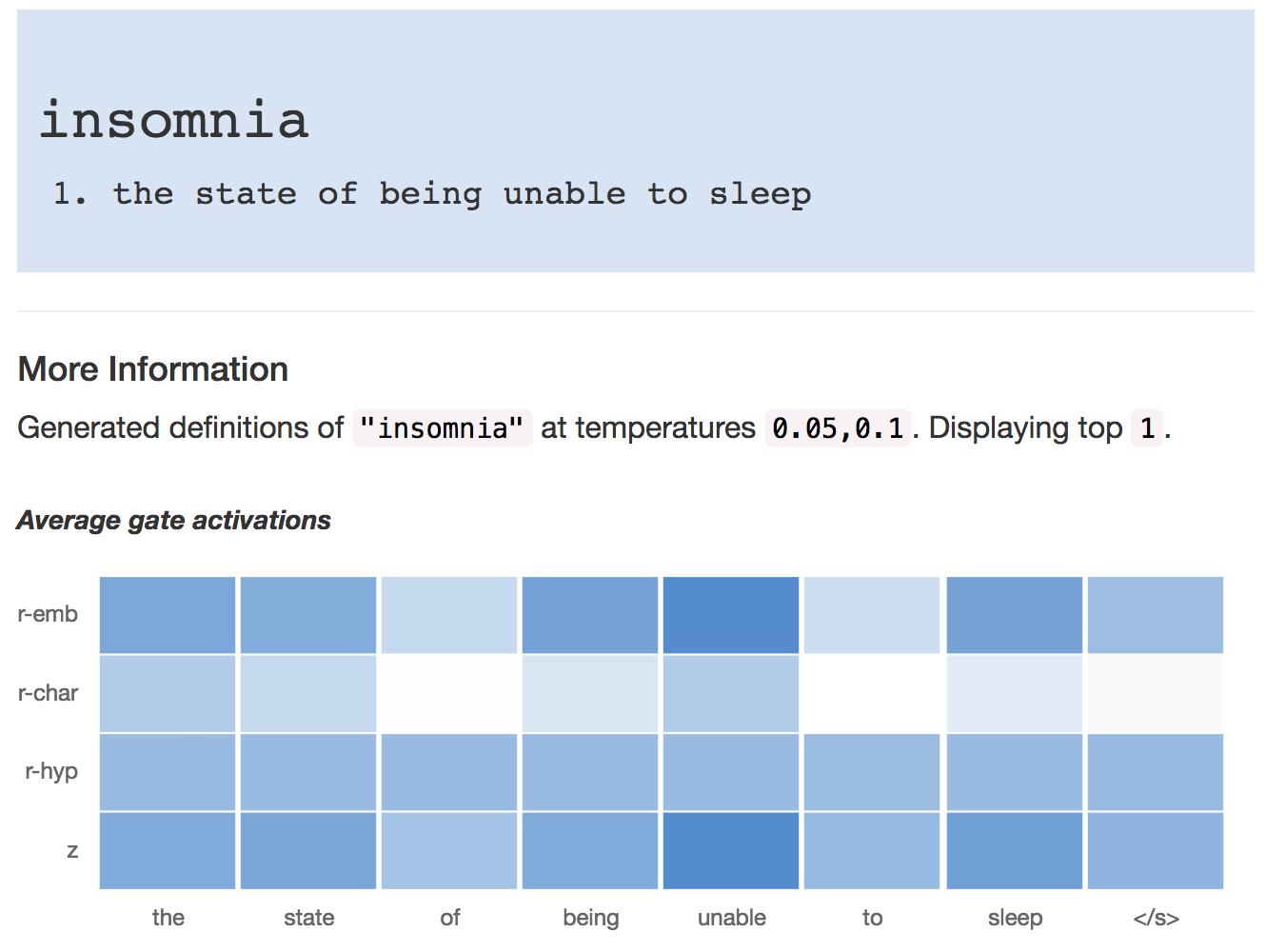
Definition Modeling: Learning to define word embeddings in natural language
Noraset, T., Liang, C., Birnbaum, L., and Downey, D.
Poster, AAAI 2017
Representation and Computation in Cognitive Models
Forbus, K., Liang, C., and Rabkina, I.
Journal, Topics in Cognitive Science 2017
Learning Paraphrase Identification with Structural Alignment
Liang, C., Paritosh, P., Rajendran, V., and Forbus, K.
Oral Presentation, IJCAI 2016
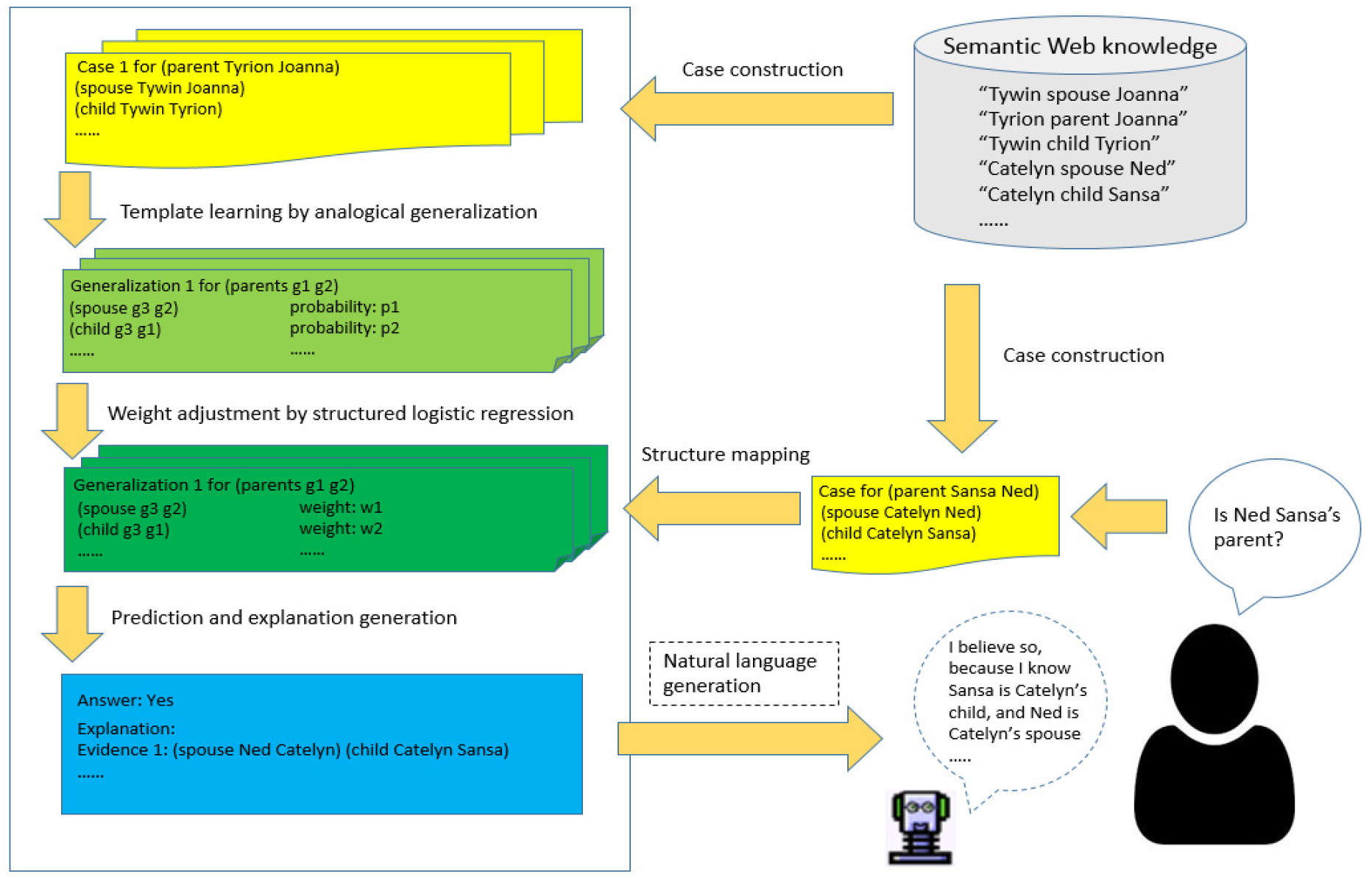
Learning Plausible Inferences from Semantic Web Knowledge by Combining Analogical Generalization with Structured Logistic Regression
Liang, C. and Forbus, K.
Oral Presentation, AAAI 2015
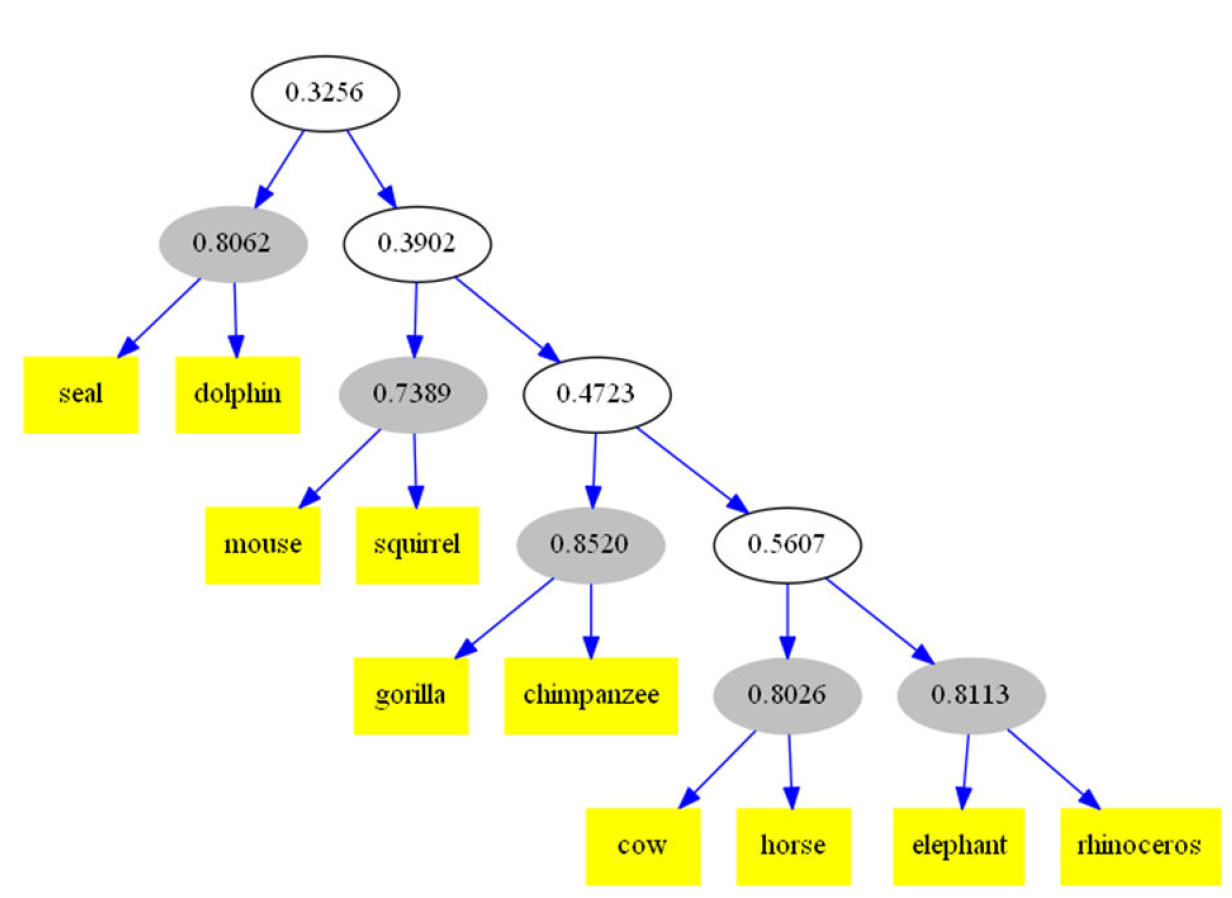
Constructing Hierarchical Concepts via Analogical Generalization
Liang, C. and Forbus, K.
Poster, CogSci 2014